
Simultaneous Extrinsic Contact and In-Hand Pose Estimation via Distributed Tactile Sensing
Prehensile autonomous manipulation, such as peg insertion, tool use, or assembly, require precise in-hand understanding of the object pose and the extrinsic contacts made during interactions. Providing accurate estimation of pose and contacts is challenging. Tactile sensors can provide local geometry at the sensor and force information about the grasp, but the locality of sensing means resolving poses and contacts from tactile alone is often an ill-posed problem, as multiple configurations can be consistent with the observations. Adding visual feedback can help resolve ambiguities, but can suffer from noise and occlusions. In this work, we propose a method that pairs local observations from sensing with the physical constraints of contact. We propose a set of factors that ensure local consistency with tactile observations as well as enforcing physical plausibility, namely, that the estimated pose and contacts must respect the kinematic and force constraints of quasi-static rigid body interactions. We formalize our problem as a factor graph, allowing for efficient estimation. In our experiments, we demonstrate that our method outperforms existing geometric and contact-informed estimation pipelines, especially when only tactile information is available.
In-Context Iterative Policy Improvement for Dynamic Manipulation
Attention-based architectures trained on internet-scale language data have demonstrated state of the art reasoning ability for various language-based tasks, such as logic problems and textual reasoning. Additionally, these Large Language Models (LLMs) have exhibited the ability to perform few-shot prediction via in-context learning, in which input-output examples provided in the prompt are generalized to new inputs. This ability furthermore extends beyond standard language tasks, enabling few-shot learning for general patterns. In this work, we consider the application of in-context learning with pre-trained language models for dynamic manipulation. Dynamic manipulation introduces several crucial challenges, including increased dimensionality, complex dynamics, and partial observability. To address this, we take an iterative approach, and formulate our in-context learning problem to predict adjustments to a parametric policy based on previous interactions. We show across several tasks in simulation and on a physical robot that utilizing in-context learning outperforms alternative methods in the low data regime. Video summary of this work and experiments can be found here.

Estimating Deformable-Rigid Contact Interactions for a Deformable Tool via Learning and Model-Based Optimization
Dexterous manipulation requires careful reasoning over extrinsic contacts. The prevalence of deforming tools in human environments, the use of deformable sensors, and the increasing number of soft robots yields a need for approaches that enable dexterous manipulation through contact reasoning where not all contacts are well characterized by classical rigid body contact models. Here, we consider the case of a deforming tool dexterously manipulating a rigid object. We propose a hybrid learning and first-principles approach to the modeling of simultaneous motion and force transfer of tools and objects. The learned module is responsible for jointly estimating the rigid object’s motion and the deformable tool’s imparted contact forces. We then propose a Contact Quadratic Program to recover forces between the environment and object subject to quasi-static equilibrium and Coulomb friction. The results is a system capable of modeling both intrinsic and extrinsic motions, contacts, and forces during dexterous deformable manipulation. We train our method in simulation and show that our method outperforms baselines under varying block geometries and physical properties, during pushing and pivoting manipulations, and demonstrate transfer to real world interactions.

This&That: Language-Gesture Controlled Video Generation for Robot Planning
We propose a robot learning method for communicating, planning, and executing a wide range of tasks, dubbed This&That. We achieve robot planning for general tasks by leveraging the power of video generative models trained on internet-scale data containing rich physical and semantic context. In this work, we tackle three fundamental challenges in video-based planning: 1) unambiguous task communication with simple human instructions, 2) controllable video generation that respects user intents, and 3) translating visual planning into robot actions. We propose language-gesture conditioning to generate videos, which is both simpler and clearer than existing language-only methods, especially in complex and uncertain environments. We then suggest a behavioral cloning design that seamlessly incorporates the video plans. This&That demonstrates state-of-the-art effectiveness in addressing the above three challenges, and justifies the use of video generation as an intermediate representation for generalizable task planning and execution.

CALAMARI 🦑: Contact-Aware and Language conditioned spatial Action MApping for contact-RIch manipulation
Making contact with purpose is a central part of robot manipulation and remains essential for many household tasks – from sweeping dust into a dustpan, to wiping tables; from erasing whiteboards, to applying paint. In this work, we investigate learning language-conditioned, vision-based manipulation policies wherein the action representation is in fact, contact itself – predicting contact formations at which tools grasped by the robot should meet an observable surface. Our approach, Contact-Aware and Language conditioned spatial Action MApping for contact-RIch manipulation (CALAMARI), exhibits several advantages including (i) benefiting from existing visual-language models for pretrained spatial features, grounding instructions to behaviors, and for sim2real transfer; and (ii) factorizing perception and control over a natural boundary (i.e. contact) into two modules that synergize with each other, whereby action predictions can be aligned per pixel with image observations, and low-level controllers can optimize motion trajectories that maintain contact while avoiding penetration. Experiments show that CALAMARI outperforms existing state-of-the-art model architectures for a broad range of contact-rich tasks, and pushes new ground on embodiment-agnostic generalization to unseen objects with varying elasticity, geometry, and colors in both simulated and real-world settings.

Integrated Object Deformation and Contact Patch Estimation from Visuo-Tactile Feedback
Reasoning over the interplay between object deformation and force transmission through contact is central to the manipulation of compliant objects. In this paper, we propose Neural Deforming Contact Field (NDCF), a representation that jointly models object deformations and contact patches from visuo-tactile feedback using implicit representations. Representing the object geometry and contact with the environment implicitly allows a single model to predict contact patches of varying complexity. Additionally, learning geometry and contact simultaneously allows us to enforce physical priors, such as ensuring contacts lie on the surface of the object. We propose a neural network architecture to learn a NDCF, and train it using simulated data. We then demonstrate that the learned NDCF transfers directly to the real-world without the need for fine-tuning. We benchmark our proposed approach against a baseline representing geometry and contact patches with point clouds. We find that NDCF performs better on simulated data and in transfer to the real-world. More details and video results can be found at https://www.mmintlab.com/ndcf/.

Visuo-Tactile Transformers for Manipulation
Learning representations in the joint domain of vision and touch can improve manipulation dexterity, robustness, and sample-complexity by exploiting mutual information and complementary cues. Here, we present Visuo-Tactile Transformers (VTTs), a novel multimodal representation learning approach suited for model-based reinforcement learning and planning. Our approach extends the Visual Transformer to handle visuo-tactile feedback. Specifically, VTT uses tactile feedback together with self and cross-modal attention to build latent heatmap representations that focus attention on important task features in the visual domain. We demonstrate the efficacy of VTT for representation learning with a comparative evaluation against baselines on four simulated robot tasks and one real world block pushing task. We conduct an ablation study over the components of VTT to highlight the importance of cross-modality in representation learning.

Learning the Dynamics of Compliant Tool-Environment Interaction for Visuo-Tactile Contact Servoing
Many manipulation tasks require the robot to control the contact between a grasped compliant tool and the environment, e.g. scraping a frying pan with a spatula. However, modeling tool-environment interaction is difficult, especially when the tool is compliant, and the robot cannot be expected to have the full geometry and physical properties (e.g., mass, stiffness, and friction) of all the tools it must use. We propose a framework that learns to predict the effects of a robot’s actions on the contact between the tool and the environment given visuo-tactile perception. Key to our framework is a novel contact feature representation that consists of a binary contact value, the line of contact, and an end-effector wrench. We propose a method to learn the dynamics of these contact features from real world data that does not require predicting the geometry of the compliant tool. We then propose a controller that uses this dynamics model for visuo-tactile contact servoing and show that it is effective at performing scraping tasks with a spatula, even in scenarios where precise contact needs to be made to avoid obstacles.

Rover Relocalization for Mars Sample Return by Virtual Template Synthesis and Matching
We consider the problem of rover relocalization in the context of the notional Mars Sample Return campaign. In this campaign, a rover (R1) needs to be capable of autonomously navigating and localizing itself within an area of approximately 50 ×50 m using reference images collected years earlier by another rover (R0). We propose a visual localizer that exhibits robustness to the relatively barren terrain that we expect to find in relevant areas, and to large lighting and viewpoint differences between R0 and R1. The localizer synthesizes partial renderings of a mesh built from reference R0 images and matches those to R1 images. We evaluate our method on a dataset totaling 2160 images covering the range of expected environmental conditions (terrain, lighting, approach angle). Experimental results show the effectiveness of our approach. This work informs the Mars Sample Return campaign on the choice of a site where Perseverance (R0) will place a set of sample tubes for future retrieval by another rover (R1).
Machine Vision Based Sample-Tube Localization for Mars Sample Return
A potential Mars Sample Return (MSR) architecture is being jointly studied by NASA and ESA. As currently envisioned, the MSR campaign consists of a series of 3 missions: sample cache, fetch and return to Earth. In this paper, we focus on the fetch part of the MSR, and more specifically the problem of autonomously detecting and localizing sample tubes deposited on the Martian surface. Towards this end, we study two machine-vision based approaches: First, a geometry-driven approach based on template matching that uses hard-coded filters and a 3D shape model of the tube; and second, a data-driven approach based on convolutional neural networks (CNNs) and learned features. Furthermore, we present a large benchmark dataset of sample-tube images, collected in representative outdoor environments and annotated with ground truth segmentation masks and locations. The dataset was acquired systematically across different terrain, illumination conditions and dust-coverage; and benchmarking was performed to study the feasibility of each approach, their relative strengths and weaknesses, and robustness in the presence of adverse environmental conditions.

Multi-Fingered Active Grasp Learning
Learning-based approaches to grasp planning are preferred over analytical methods due to their ability to better generalize to new, partially observed objects. However, data collection remains one of the biggest bottlenecks for grasp learning methods, particularly for multi-fingered hands. The relatively high dimensional configuration space of the hands coupled with the diversity of objects common in daily life requires a significant number of samples to produce robust and confident grasp success classifiers. In this paper, we present the first active deep learning approach to grasping that searches over the grasp configuration space and classifier confidence in a unified manner. We base our approach on recent success in planning multi-fingered grasps as probabilistic inference with a learned neural network likelihood function. We embed this within a multi-armed bandit formulation of sample selection. We show that our active grasp learning approach uses fewer training samples to produce grasp success rates comparable with the passive supervised learning method trained with grasping data generated by an analytical planner. We additionally show that grasps generated by the active learner have greater qualitative and quantitative diversity in shape.

Learning Continuous 3D Reconstructions for Geometrically Aware Grasping
Deep learning has enabled remarkable improvements in grasp synthesis for previously unseen objects viewed from partial views. However, existing approaches lack the ability to explicitly reason about the full 3D geometry of the object when selecting a grasp, relying on indirect geometric reasoning derived when learning grasp success networks. This abandons common sense geometric reasoning, such as avoiding undesired robot object collisions. We propose to utilize learned 3D reconstruction to enable explicit geometric awareness in a grasping system. Our reconstruction network directly predicts the signed distance for points queried near the object. We leverage the structure of the reconstruction network to learn a grasp success classifier which serves as the objective function for our grasp planner. These are combined into a constrained, continuous grasp optimization problem that plans grasp while avoiding undesired collisions. Our results show that explicitly learning to reconstruct the 3D geometry outperforms alternative formulations for partial-view information based on real robot execution.

Multi-Fingered Grasp Planning via Inference in Deep Neural Networks
We propose a novel approach to multi-fingered grasp planning leveraging learned deep neural network models. We train a voxel-based 3D convolutional neural network to predict grasp success probability as a function of both visual information of an object and grasp configuration. We can then formulate grasp planning as inferring the grasp configuration which maximizes the probability of grasp success. In addition, we learn a prior over grasp configurations as a mixture density network conditioned on our voxel-based object representation.
We show that this object conditional prior improves grasp inference when used with the learned grasp success prediction network when compared to a learned, object-agnostic prior, or an uninformed uniform prior. Our work is the first to directly plan high quality multi-fingered grasps in configuration space using a deep neural network without the need of an external planner. We validate our inference method performing multi-finger grasping on a physical robot. Our experimental results show that our planning method outperforms existing grasp planning methods for neural networks.
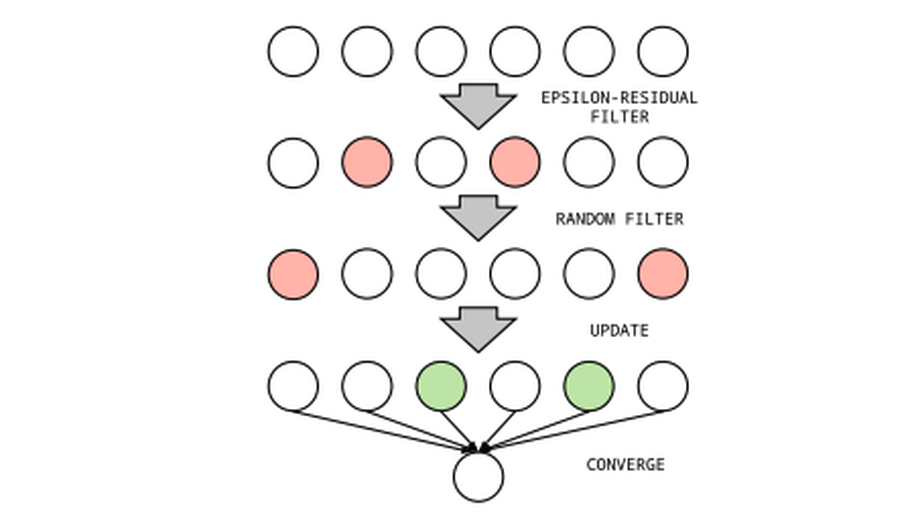
Message Scheduling for Performant Many-Core Belief Propagation (Best Student Paper Finalist)
Belief Propagation (BP) is a message-passing algorithm for approximate inference over PGMs. We demonstrate that the scheduling of those messages on many-core parallel systems must be considered for performant (i.e. fast and convergent) algorithmic performance. To this end, we introduce a novel, many-core centric scheduling which we demonstrate outperforms existing scheduling methods on the GPU.